

.svg)




















“We’re not lowering our standards. We’re applying them in a way that allows us to step back when markets deliver safely, and step in when they don’t…..This is a shared challenge. One we should all meet with confidence.”
David Geale, Payment Systems Regulator (PSR)
This recent statement from the PSR, part of the Financial Conduct Authority (FCA) should be taken as clear encouragement from the UK regulator to be confident in innovating and testing new approaches, even for financial crime compliance. Financial institutions the world over are already complying with stringent fincrime regulations and even testing some early-stage artificial intelligence (AI) use cases. But the pervasive hesitancy to branch out to implementing new agentic AI or automated decisioning seems to be based on historical perceptions of the role of regulators as constraining technology adoption – not the current reality that is explicitly outcomes-based.
Recent input from the FCA has reinforced that firms using AI must continue to display strong outcomes within financial crime compliance. The regulator clearly states that innovation is heavily encouraged, but it should not be at the expense of effective anti-money laundering controls. As AI becomes more widely adopted in anti-money laundering (AML) processes, firms are still under increasing pressure to show that their outcomes are accurate, risk-based, and explainable under FCA supervision.
The FCA focuses on how it can regulate the outcome, rather than the technology used to obtain it. Financial firms have already begun integrating AI within their financial crime compliance operations understanding that the regulatory expectation remains the same: all organisations must have the ability to show evidence that led to their final decision. This becomes increasingly important when firms begin implementing agentic AI and automated decisions. Auditability and transparency in risk-based decision making is the foundation of the outcomes-based approach. This approach from the FCA is designed to reduce risk and build trust with stakeholders. Any new AI innovations must be developed with the evidentiary trail embedded from day-one.
At this stage of AI adoption, firms should be prioritising developing agentic AI and automated decisioning, which has been proven to deliver tangible benefits in fincrime compliance use cases. However, a compliance-first approach must remain at the heart of new AI rollouts.
Compliance-first use of agentic AI
AI-driven insights and automations using agents should provide a clear audit trail, to paint a precise picture and highlight how a specific decision was made. This transparency ensures that all firms can adopt new technology quickly and with confidence in accuracy, efficiency, and compliance and avoids historical patterns where regulation has lagged behind the rate of technological advancement.
In this example insight, we see clear labelling of AI outputs and insights, with an analyst-level explanation of exactly what was discovered and how, and most importantly – links back to the underlying data for validation.
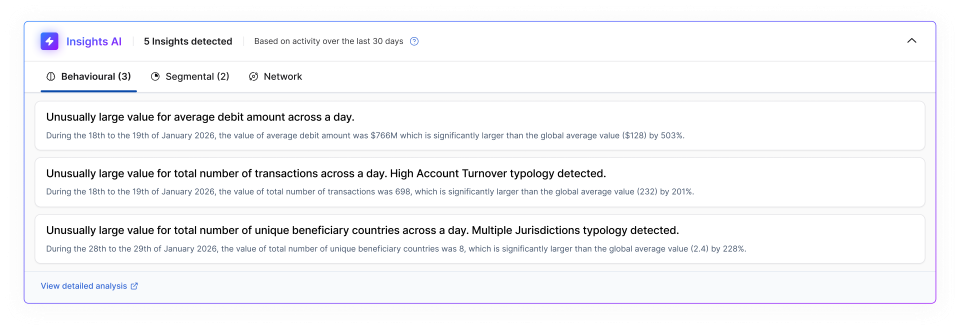
Testing for improved outcomes in financial crime compliance
The specifics of testing across AI for AML does differ by model type, but the core principles remain the same. There are different error types to address. Types 1 (false positives) and 2 (false negatives) are relatively well understood by most teams., but where there needs to be more focus is Type 3: where the underlying reasoning is flawed, even if the result is correct. This could be a true positive result, but that is confusing correlation of irrelevant data points for causation. There are similar issues with outputs from language models, although these are usually not as cleanly identified. This is important because while the system may appear sound in the isolation of a testing environment, once pushed live is detecting the wrong vectors. Without a correction in the testing phase, these errors reach production and become compounded as models continue to learn on the incorrect underlying assumptions.
LLM testing
Large Language Models (LLMs) suffer from three kinds of errors:
- Omission
- Detail
- Hallucination
In the example image above, these could manifest in the following ways.
- Errors of omission mean that data has been incorrectly discounted, such as missing a true positive in AML. This could be that the AI failed to pick up on the unusually large value for total number of unique beneficiary countries across a day.
- Errors of detail are assertions or ‘facts’ that are correct, but the maths is incorrect, or a key piece of information is missing. This could be that the AI did pick up the unusually large number of unique beneficiary countries but failed to inform the analyst of all the countries included in that ‘large number’ and even failed to note sanctioned markets.
- Full blown hallucinations are also known as errors of fact, and in this example could be that the AI states transactions were made to unique beneficiary countries that were not in the mix or in fact were not posted at all.
Classification model testing
Classification models also suffer from three kinds of errors.
In the context an AML typology, such as higher total transaction account turnover, these could present as:
- Type 1: False positive. The total number of transactions was insufficient to meet the threshold, but an alert was still triggered.
- Type 2: False negative. A total number of transactions did not trigger an alert even when it should have.
- Type 3: Correct alert, wrong reasoning. In this case, the higher account turnover typology should have been detected, but the data used to drive the alert was incorrect or wrongly labelled.
Type 3 errors often occur when AI models wrongly assume that a correlated data point is in fact a causation vector. In this example, perhaps all the high-risk transactions identified in the testing occurred at the same time of day each day. The timing alone of the transaction would not make it risky, but without human validation this error could creep into production and then wrongly assume all transactions at that time of day are inherently risk (causing huge false positives) and wrongly assume that transactions outside that window are less risky (causing risk exposure on false negatives).
In financial crime compliance, this same principle can be applied. Even if a model detects suspicious behaviour and the outcome may seem correct, if the underlying risk-assessment is flawed it should not pass testing and validation, and it would still fail under regulatory scrutiny.
Explainability techniques in AI for AML
Testing for explainability is a core tenant of fincrime AI validation in pre-production. Financial data explainability includes statistics, raw transactions, and other contributing information such as free text or analyst notes. These data sources need to be constructed or labelled in a way that an AI agent can pull these into an audit trail, so they can be collated for a human to review and approve any decisions.
Explainability techniques vary across different types of AI models. But in all cases, the end user must be able to go back to the data and be confident that the decision is good, given their regulatory accountability.
Validation of large language models (LLMs) in AML requires that every financial crime compliance team can analyse any statement of fact from the AI, back to the original source of the data. A technique called Retrieval Augmented Generation (RAG) makes it possible to connect the activity history, customer records, or the transactions directly to the conclusion. For example, if a transaction is flagged as sending funds to a sanctioned individual to confirm it as a statement of fact, RAG would need to confirm that the sanctioned entity exists, the funds existed in the originator’s account and how they arrived there. When conducting these checks, it is crucial to ensure that that necessary data is available for fact checks.
Human-in the-loop approaches and risk-based assessment
Making sure that human expertise remains available is a key aspect as it plays a critical role in this entire process. 1LoD and 2LoD analysts understand common money laundering typologies and should be the humans-in-the-loop help define normal behaviour. Domain knowledge should remain a fundamental part of AML operations and AI model validation, so that those patterns can be investigated and confirmed or discounted, to continuously train models, adapt risk-based approaches, and reduce false positives.
While some use cases can be fully automated, human-in-the-loop is critical for any entity or transaction deemed high risk. What constitutes high risk should be defined by a financial institution’s risk-based assessment (RBA) under the European Union (EU) Artificial Intelligence Act. The justification of what is high- or low- risk is the result of a robust RBA. The effort of a good RBA makes it easier to find use cases for automation across three categories:
- Full automation, totally autonomous
- Partial automation, human supported
- Human-led
Alongside a focus on outcomes, the FCA has transitioned to a risk-based approach. To enact this within financial crime, any AI that is implemented must be underpinned by a strong risk-based assessment that defines what is classed as elevated risk, and what may be classed as minimal risk.
In scenarios that are classified as high-risk, a human-in-the-loop decision is mandatory. AI can be leveraged for low-risk alert auto-discounting. But when AI-driven pattern detection generates an alert classified as high-risk, a human must be able to actively review the reasoning and be the responsible part for any decision to discount or alert. This remains constant with the expectations under the EU AI Act, which may still be applicable to UK financial services firms if they support any customers within the EU.
While low risk customers and transactions allow for more automation to flow, there still must be human oversight in the form of spot checks and sampling. Best practice is to check that your systems are acting as you would expect.
What constitutes high risk or low risk is not prescribed by the regulator. It is based on an individual financial institution’s risk-based assessment. Regulators will give guidelines, but it is not definitive rules. A strong risk-based assessment should feed into everything that fincrime teams do with AI, including model validation and outcomes-based testing, to ensure the focus stays on results and not technology.
Validating and verifying AI outputs for financial crime compliance
Whether relying on in-house data scientist or third-party experts at partner, trust is important for understanding the source of data, validation, and testing processes including the underlying test data itself.
Model results should be tested against institutional knowledge regularly. This is because if an experienced analyst manages to identify risks that the system does not highlight, it indicates that the AI may need to be re-adjusted. Checks should focus on finding both false positives and false negatives within the AI results.
Model validation cannot be solely dependent on data scientists. Organisations should expect good tension between experts in AI and financial crime compliance professionals to understand if the AI results align with institutional expertise. Consider it a good litmus test for outcomes-based approaches. Compliance users will need an explanation that is clear so that they can understand the reasoning as to why a result was produced, and to confirm that the AI system supports the intended outcome.
The future of AI for AML: compliance first
While the FCA actively encourages the use of AI for AML, it does so with clear guardrails. For AI to be effective in financial crime compliance, it must be implemented with a compliance-first mindset. This means managing errors and embedding explainable, auditable AI into compliance workflows from sandbox through to production.
We have seen the first instances of regulatory rebuke emerge from failures in AI validation and explainability: the Federal Court of Australia just presided over an AML compliance judgement for the Australian Securities and Investments Commission, in which it clearly cautioned on the use of LLMs in summarising large documents without human judgement to validate the outcomes. The judgement focused specifically on the use of AI to navigate material provided to the legally responsible humans-in-the-loop, stating;
"There is nothing inherently objectionable in obtaining such assistance, but what ought not occur is that this development becomes an excuse for a failure to instil discipline in the provision of information to directors or leads to a quiet normalisation of private reliance by them upon computer-generated distillations, unregulated by any agreed policy."
The judgement acts as an excellent caution, providing clear recommendations on how to avoid similar failures:
- Consideration of extent to which directors must read, understand and engage with the information they receive in their capacity as board members – boards must control the information they receive
- Directors must take reasonable steps to place themselves in a position to guide and monitor the management of the company – directors cannot rely upon an inability to cope with the volume of information they receive
- Directors must exercise control – consideration of impact of artificial intelligence on corporate governance practices – the use of technology may assist comprehension, but it cannot displace human judgment.
At Napier AI, we have developed an AI taxonomy across use cases for compliance-first AI in AML include:
- Insights: supplying missing information, e.g. typology detection or advanced name matching to watchlists
- Advisory: suggested actions, e.g. review/discount, update risk scorecard, change your rules
- Investigatory: surfacing data in investigations, e.g. ask the system to ‘show me’ or summarise
- Explanatory: detailed alert descriptions e.g. on discount decision reasons or high-risk behaviour explanations
All of these meet the regulator aims around improving outcomes for AML whilst maintaining humans-in-the-loop and clear explainability and audit trails.
Each of these use cases have different requirements for explanation and validation.
- Insights: requires supporting data including statistics, to justify that this data leads to this conclusion, and inbuilt feedback loops to train on acceptable insights
- Advisory: also needs data supported conclusions but also requires back-end monitoring to validate if output (a recommended action) was agreed upon or actions by the user. This may require the measurement of a range of inferred data points across soft and strong signals
- Investigatory: seek to identify LLM-based errors in interpreting requests from analysts and presenting data back. LLMs need to be hooked into the right data sources and specific to the use case (AML) to avoid errors
- Explanatory: requires the right explanation, for the right models, in the right place. For high-risk activity, this means the ability to drill down to underlying data
Trends in AI for AML
GenAI has been emerging for years and is now at the stage that it can create great explanations and summaries. For fincrime, the continuous validation of underlying facts is essential. Even the latest GenAI models are prone to errors across omission, detail and fact, and layering in speech and video capabilities doesn’t solve the issue. If financial institutions can build in the continuous validation loop there’s no reason they can’t be benefiting from GenAI right now in use cases such as GenAI summaries for decision records.
Copilots are quickly becoming obsolete in fincrime compliance. They are context unaware, sit outside of workflows, and too generic to be useful or compliant. ‘Fast failers’ in the industry invested time, money, user testing from which did emerge a (relatively narrow) set of use cases that do not sit within the compliance function specifically. For fincrime compliance, it is essential to have context-specific information, and the goal is to replace isolated actions with agents. If fincrime teams do not already have a copilot in place they could skip this generation of AI and land directly in agentic.
Technological leapfrogs are common when organisations are behind the adoption curve, allowing them to accelerate to the next generation of technology after its initial iteration. We see this in payments for example, where the UK - as one of the earliest adopters of instant payments – built its faster payments system on the ISO 8593 and had to migrate to the modern, rich data ISO 20022 standard in 2023, whereas as latecomers to the real-time rails, the US built on ISO 20022 from the get-go.
And while agentic AI is the new frontier, I caution fincrime teams to do their due diligence in solution evaluation. True agentic AI needs agency to act and independent ability to look at data and action an appropriate outcome. Many offerings in the market are not true agentic, but more simple robotic process automation (RPA) solutions.
As outlined, many fincrime compliance use cases need a human-in-the-loop in the final decision steps of an action. Agents can gather the information to support an investigation, with strong guardrails around data access, and a human-in-the-loop in to sign off the final action.
In general, financial institutions are keen to benefit from AI but need to design the best way to implement agentic and generative AI into their workflows. I advise teams to use AI technology to do new things, not just automate existing processes. We should learn from previous generational shifts in technology such as the advent of cloud: many firms got bogged down recreating their existing technology stacks in new environments and did not leverage the opportunity at hand to rethink the approach and drive operational gains. As fincrime professionals, we have a generational opportunity to drive tangible value in terms of accuracy, effectiveness, and efficiency and even outsmart organised crime.
RegTech sandboxes for AI testing
Regulators are increasingly providing opportunities to access testing environments and compute power to accelerate model validation and model design techniques, as well as new agentic approaches, with a view to accelerating the implementation of AI for AML.
The FCA Supercharged Sandbox is a great example. Napier AI recently presented its new approach to AI model testing under ‘Project Theseus’ as part of the FCA Supercharged Sandbox Showcase. Project Theseus included two tests: pattern mining and fluid dynamics, which use novel frequency-based AI algorithms on large-scale synthetic financial data sets to detect money-laundering typologies more effectively than traditional rules-bases systems, and with significantly reduced compute power.
These kinds of initiatives are often open to all regulated entities, and organisations only need to apply for access. Preparing for the access window once granted is key to make the most of the opportunity. Joining any existing working groups and attending current sprints or presentation days is a good first step. Once an access slot is granted, it is important to dedicate a team and to define a clear test including a robust hypothesis. Allocating the right resource is crucial because most access is within a time-bound ‘sprint.’
Proactive engagement with the regulator is a core pillar of a compliance-first approach to AML and should be prioritised by fincrime teams looking to improve their AML outcomes.
Collaboration with regulators plays a key role in ensuring that AI-driven AML outcomes remained aligned with FCA expectations around transparency, validation, and accountability.
The FCA’s use of AI is art of a wider global shift in tackling money laundering. Discover further international context on this development with our blog; Countries Poised to Win the Fight Against Money Laundering With AI







