

.svg)






















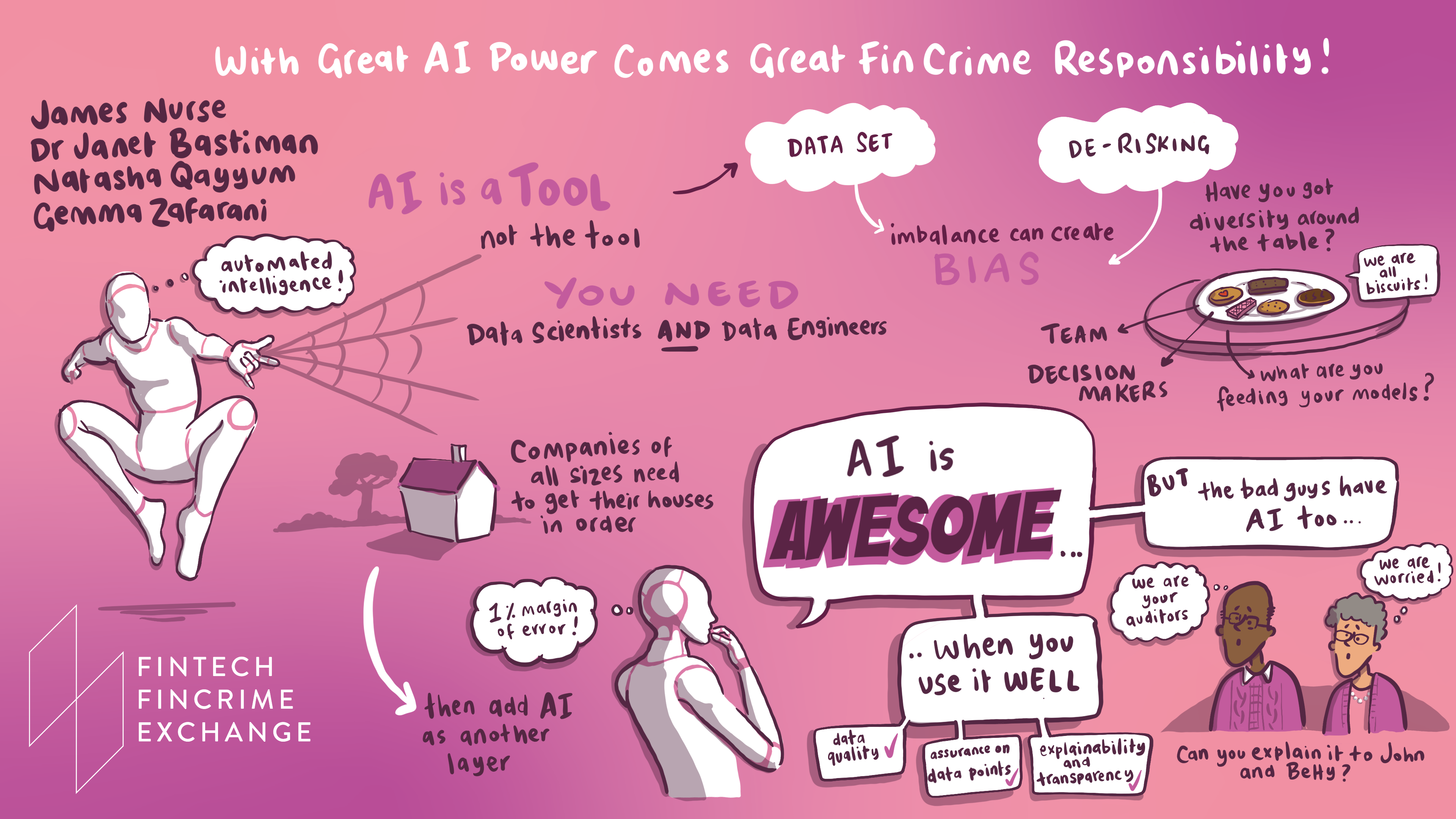
I was pleased to join FINTRAIL, who organised the FFECON22 conference last month, and to be invited to join a panel moderated by FINTRAIL’s Managing Director, James Nurse, where we tackled some of the less-discussed issues of Artificial Intelligence (AI), joined by two of our amazing peers:
- Natasha Qayyum, Risk Intelligence Analyst, GoCardless
- Gemma Zafarani, Data and Analytics Lead - Financial Crime, NatwestGroup
Read on for some of the key thought-provoking highlights we raised:
AI for anti-financial crime: with great power comes great responsibility
A lot of people see AI as a great thing in the fincrime space, and it can have this perception of being the ‘magic fairy dust’ that solves all the problems. But one thing that's not talked about often enough with bringing AI into financial crime compliance processes is how to do it right and what can happen if things go wrong.
Lack of diversity in Data Science teams
We talked a lot about neurodiversity in teams, specifically that you need to have diversity of thought to produce good solutions. Often the worst AI solutions come about when you don’t have that diversity, so the impact of the end user isn’t properly considered.
We skirted around some of the problems the UK has seen, without mentioning names, where financial institutions have rolled out solutions in transaction monitoring or screening that caused disruption for customers. Bank accounts being suspended is one such disruptive consequence that has hit some of the poorest and most marginalised people in the UK.
If you’re profiling people for anti-money laundering purposes and the typologies or personas are too tight, you risk producing a solution that unfairly marks a group of people as suspicious. Irregular financial behaviour isn’t always suspicious, and in real life, people can receive their income in many ways.
For example, a single parent living in one of the poorer areas of a city may have irregular income, receive cash-in-hand payments from employers, and may even have an unusual-sounding surname for the area. None of this may be out of the ordinary, but a strict set of rules or a poorly implemented AI system may flag these accounts and possibly suspend them, cutting that person off from their money.
While you may not be able to counter every scenario there are some general principles that apply: testing, tuning, explainability and human oversight all combine to give the best possible outcome for your systems. Diversity underpins all of these techniques.
This also goes for financial institutions where the customers are businesses, as systems that are incorrectly configured may over-protect larger businesses at the expense of smaller ones who have less regular ‘typical’ financial behaviour.
The problem with using synthetic data to train AI models
The use of synthetic data, while it has its place, can’t beat good quality, real data when it comes to catching criminals and understanding evolving criminal typologies. The main issue is that we simply don’t have enough good quality, real data.
By working hand-in-hand with augmented intelligence, analysts can dig through unusual activity as it’s flagged. This ties in well with the concept of explainability too as scenarios like this highlight the critical nature of creating AI models that do more than just churn out a number. Analysts need to understand outputs to work meaningfully with AI.
A great example of the lack of good data came from Gemma, who highlighted that the small number of positive hits we have from which to train AI models can cause issues by building in unintentional biases to the system. Say a positive hit for suspicious financial activity comes from ‘John’ from Italy and you only have a handful of positive hits to train the AI, then the system won’t be able to extrapolate the key behaviours correctly. In this scenario, you’re likely to have a situation where everyone in Italy called John is assigned extra weighting that they might be involved in some sort of financial crime.
When you’ve got these weightings creating very unbalanced datasets, it becomes very difficult to extrapolate meaningful analyses without marginalising anyone that appears to match those few positive instances, whether in their transactions or in other features.
The trouble is AI systems need that positive bias to catch people who are committing financial crimes, so testing and explainability of AI systems are crucial to get the balance right to minimise the volume of false positives.
Should we be training AI models to be more ‘human’
You don’t need a degree in human psychology to train AI models, but an understanding of data is critical because raw transaction data doesn’t encapsulate the behavioural context or intent behind that transaction.
You get behavioural analytics from the transactions, and you get customer personas partially from Know Your Customer (KYC) data. However, to build an AI model you need a good understanding of what is and isn’t relevant, the providence of that data, and how it has changed since it was originally captured up to the point that you are dealing with it.
Those are the fundamentals of what data science is - that analytical and statistical process of understanding all that about data, picking the right fields to build the models, and then interpreting those models in a way that can be understood by the end user.
If analysts and other business users have a deeper understanding of what's going on, that helps enormously in identifying suspicious patterns of behaviour. Therefore much of what we do at Napier by providing explainable AI-derived insights facilitates that understanding and gives the user that power. The analyst must be able to fill in the gaps and the human psychology side of things, as they have that relationship with their customers.
When is due diligence on its own not enough?
Instances like the Tinder Swindler story highlight how easily customers can be defrauded when the human insight is absent from due diligence checks and when these checks don’t go beyond basic customer confirmation to authorise a transaction.
This happens often in fraudulent transactions against the elderly. If the customer doesn’t know the transaction is fraudulent, basic checks to identify the customer and gain their consent for the payment aren’t enough to prevent crime.
There might be more to the transaction, but we can’t incorporate social history or activity found on platforms like Facebook and Tinder in the models, making it impossible to decide if a transaction is ‘good’ or ‘bad.’ Something else must fill that gap, whether this is thorough KYC processes or more thorough handling of anomalies by analysts. AI can help, because if your rules and AI optimise other processes, analysts can dedicate time to cases where human involvement is needed to investigate.
How does machine learning work if there’s not enough data?
If you've only got 11 instances of a red flag, these are few enough that a human needs to step in and do supervised learning for the model with pre annotated datasets.
Alternately, you’d look to do unsupervised learning where you're looking for anomalies without having labelled data - which is one of the methods Napier uses.
Napier’s AI insights uses a combination of supervised and unsupervised learning techniques to look for behavioural changes as well as defined typologies to provide the best of both worlds depending on the data available.
Is AI biased towards marginalised people?
If you are profiling customers and you’re not aware of the differences in why different groups behave as they do, this can translate into gaps in your rule system or your AI set up.
Systems that are set up for people that are in regular full-time employment will most likely flag those whose transactions do not conform to expectations.
For example, take irregular payments: a person working zero hours contracts won’t know from one week to the next how much money they are bringing in. Their account at the bank will show many irregular payments in and out of their account, which could be flagged as suspicious.
The AI model will continue to flag these types of transactions as irregular (or suspicious) if there is no human involvement to teach and test it differently.
Additionally, without diversity in the team and of thought, it’s possible to create a model that appears to function brilliantly according to your internal testing criteria and performs well against some customer data, but then issues arise when that system goes live and processes real data.
What do businesses risk by having the wrong type of AI?
Poor AI model performance can result in a poor customer experience if red flags and account suspensions result in customers unable to access their money. There may be reputational damage or a decrease in trust for these banks, and their business may be impacted if customers move the money elsewhere.
No matter if you’re using AI or rules, or using them interchangeably, it is important to base your systems on typologies that are up-to-date, to consider multiple dimensions to data, and to consider behaviour in context to avoid making mistakes that could erode trust or customer satisfaction.
Diversity of thought in the building and testing stages is crucial to the performance of any AI model, but equally important is the ongoing involvement of humans to continually provide feedback and fine-tune it, and to provide social context for raw transaction data. Without these things, AI can’t deliver the considerable returns and efficiencies that have earned it such a favourable reputation in the fincrime world.
%20(1).png)
We recently released a 12-step guide to AI implementation created by our Chief Data Scientist, Dr Janet Bastiman, and FINTRAIL's Managing Director, James Nurse. This comprehensive resource addresses some of the most common challenges financial institutions face in this journey, and assesses the current regulatory landscape around the use of AI.
Access the guide here.
Discover next-generation financial crime compliance technology
Book a demo of our solutions or get in touch to find out how Napier can rapidly strengthen your AML defences and compliance capabilities.
Photo by Nathan Watson on Unsplash






